Databases
A database consists of multiple components:
- transport layer
- query processor
- execution engine
- transaction manager: coordinates, schedules and tracks transactions
- lock manager: guards access to resources and prevents concurrent accesses that violate data integrity
- log manager: holds a history of operations
- storage engine
- RocksDB
Types of DB's
- OLTP: transactions
- OLAP: analytical
- HTAP: hybrid of transactions and analytics
Data Layout
- Row oriented
- Column oriented
- Wide columns
- Big table or Hbase
- Stored in multidiensional maps
- Columns are grouped into column families and inside each column family, data is stored row-wise
- Good for storing data retrieved by key(s)
Recovery
- WAL
- Write-ahead log (WAL) also know as commit log, is an append-only auxiliary disk-resident structure used for crash amd transaction recovery
- Each WAL record has a unique, monotonically increasing log sequence number (LSN)
- Shadow paging: copy-on-write where new content is published on shadow page and is commited on pointer flip
- Steal and force policies
- ARIES
- Steal/no-force recovery algorithm
- uses WAL records to implement repeating history during recovery
- Creates compensation log records during undo to avoid repeating work in case of another failure
Deletion
- Most DB's use a delete marker or tombstone instead of deleting directly. When doing garbase collection it can remove this
Cache
- Eviction: When ti removed cache that no longer needs
- Eviction algorithms
- FIFO: first in, first out, most naive one
- LRU: least recently used, places the cache on the back of eviction list when accessed. can be expensive to reorder on high transaction db's
- 2Q: two-queue LRU: defines 1 cache queue and another for ones with frequent access
- LRU-K: keeps track of last K accesses
- Clock: efficient algorithm
- LFU: trackspage reference events, great for db's under heavy load as it gives preference for frequently accessed items
Concurrency Control
- Set of techniques for handling interactions between concurrently executing transactions
- Categories:
- Optimistic concurrency control: allows concurrent reads and writes and afterwards checks if the result is serializable. In case of conflict one of the conflicting transactions aborts. Good when the conflicts are rare as retries are expensive
- Multiversion concurrency control: guarantees a consistent view of the datbaase at some pointin the past
- Uses locking, scheduling and conflict resolution (i.e 2-phase locking) or timestap ordering
- Used for implementing snapshot isolation
- Pessimistic concurrency control: uses both lock-based and nonlocking conservative methods. The first disallow other transactions access to data records. The seconds keeps a list of operations and only locks in case of detecting an unfinished transaction for the requested data record
- Timestamp ordering
- Lock-base concurrency control: pessimistic concurrency control that uses explicit locks rather than schedules
- Growing phase: acquires locks for transactions. No locks released
- Shinking phase: all acquired locks are released
- Deadlocks can occur, where two transactions block each other. To avoid this we can use:
- Wait-die: a transaction can be blocked only by a transaction with a higher timestamp
- Wound-wait: a transaction can be blocked only by a transaction with a lower timestamp
Locks
- Checks for logical integrity
- Heavier than latches and are held for the duration of the transaction
Latches
- Checks for physical integrity
- Types
- Readers-writer lock: grants exclusive read/write access
- Latch crabbing:
- Blink-trees
Data Consistency
The CAP Theorem is fundamentally about replication, specifically network failures during replication.
CAP theorem
- Consistency: on a read receive the most recent item
- Availability: receive non-failing response
- Partition tolerance: system operation despite network traffic disruption between nodes
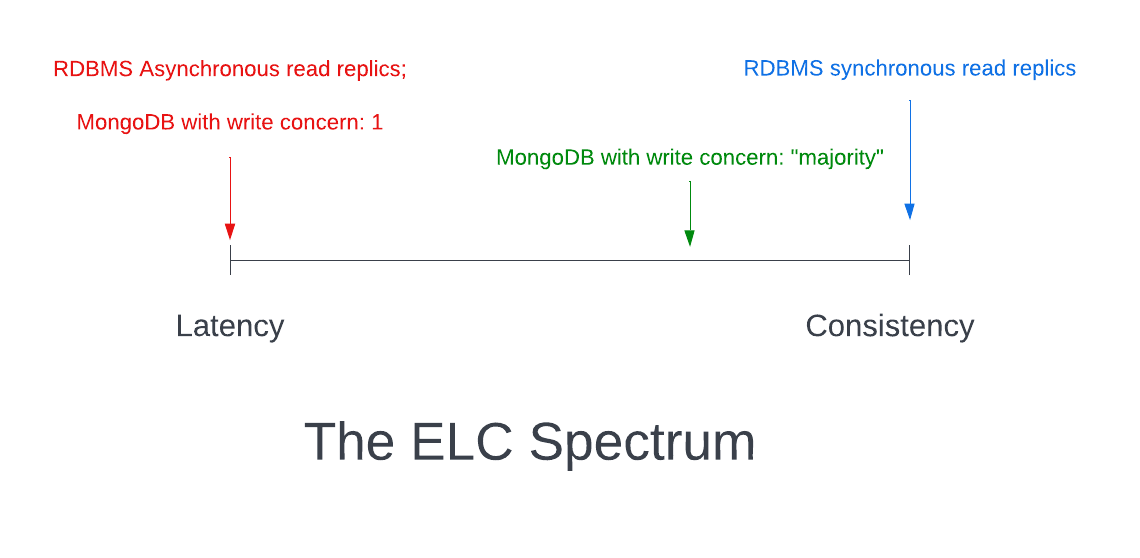
PACELC theorem
- Extension of CAP
- It states that in case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C) (as per the CAP theorem), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C). (source wiki)
Transaction guarantees (ACID)
ACID refers to a set of guarantees about the behavior of a database when combining multiple operations in a single, logical operation (often called a “transaction”).
- ATOMICITY: all operations succeed or fail together
- CONSISTENCY: the database is in a valid state following the transaction
- ISOLATION: concurrent transactions are treated as executed sequentially
- Durability: a committed transaction will be saved even in the event of a failure
Read and Write anomalies
- Dirty read: transaction reads uncommited changes from other transactions
- Nonrepeatable read: transaction queries same row twice and gets different results
- phantom read: same as nonrepeatable but for a set of rows
- lost update: occurs when multiple transactions are not aware of each other and overwrite the result of each other
- Dirty write: transaction takes an uncommited value, modifies it and saves it
- Write skew: when the individual transactions respect the constraints but their combination does not
Serializability (isolation levels)
Decides how to treat concurrent transactions on the same underlying pieces of data.
Read uncommited: weakest one, allows dirty reads
Read commited: disallows dirty reads but phantom and nonrepeatable reads are
repeatable read: only phantom reads are possible to occur
serializability: guarantees transaction outcomes will appear in some order as if transactions were execured serially
Snapshot isolation: allows transaction to observe the state changes performed by all transactions that were commited by the time it started. It commits with success only if the values it modifies did not change.
- Write skews are possible under this isolation
Linearizability
It states that once your system accepts and completes a write operation for a piece of data, all subsequent operations on that data should reflect that write.
Eventual Consistency
At a very high level, the notion of ”eventual consistency” refers to a distributed systems model where, to quote Wikipedia, “if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value.”
Writer problems
- Read amplification: need to address multiple tables to retrieve data
- Write amplification: caused by continuous rewrites by the compaction process
- Space amplification: arises from storing multiple records associated with the same key
RUM conjecture
- Cost model for storage taking into consideration 3 factors: Read, Update and Memory
Reducing two of the overheads inevitably leads to changes for tje worse in the third one, and that optimizations can be done only at the expense of one of the three parameters
- Does not take into account metrics such as latency, access patterns, implementation complexity, maintenance overhead and hardware-related specifics
Data Structures
binary search tree: not great for disk-based DB's as it has low fanout and can require frequent balacing
B-tree
- Paged B-tree: groups nodes into pages (related to SSD page)
- By allowing to store more than 2 values on each nodes it reduces the fanout and frequency of rebalances
- Lookup complexity of Log M
B-tree variants
- copy-on-write: immutable b-tree (used by LMDB)
- lazy b-tree: uses an update buffer to speed writes before merging to the tree (used by MongoDB WiredTiger)
- Lazy-Adaptative Tree: lazy b-tree but has multiple sub-trees instead of a single one
- FD-Tree
- Bw-Tree: buzzword tree, allows to solve the biggest three problems in update operations
- Cache oblivious b-trees
Log-Structure Storage
- Log-Structure Merge Tree (LSM Tree)
- Uses buffering and append-only(Immutable) storage
- Allows for fast writes as conflicts are resolved on read time
- Good for when writes are more common than reads
- Maintenance operations
- Compaction (writes the updated tables into a new one and deletes the previous)
- Tombstone is important to understand if tables old outdated data records
- Leveled-compaction: divides a table into multiple levels of different size
- Compaction (writes the updated tables into a new one and deletes the previous)
- Sorted String tables (SS Tables)
- Data records are sorted and laid out in key order
- consists of index and data files
- SSTable-Attached Secondary Indexes (SASI) allow for indexing other columns than the PK
- Unordered LSM
- Bitcask
- WiscKey
Bloom filters
- Probabilistic index. Is able to tell if a key can be on a given set or if it's definitely not
- Avoid table lookups by storing a large bit array and multiple hash functions
- Hash functions are applied to the keys of the records and sets to 1 if the key is found.
- On a search, it runs the hash functions and of all of them return 1 then it returns a positive result for a give probability. If it returns one 0 it says with 100% probability that it's not in the set
Skiplist
Breadcrumbs
- For operations that can lead to structural changes of a b-tree (split/merge) we store the references to the leaf and nodes so that we can backtrack to propagate a split or merge
Compression
- Snappy
- zLib
- Lz4
- Zstd
- brotli
- gzip
Vacuum and maintenance
- Compaction
- vacuum
- general "maintenance"
Concurrency vs Parallel
- Concurrency is like having two queues to a single coffee machine
- Parallell is like having two queues to 2 coffee machines
The 8 fallacies of distributed programming
- The network is reliable;
- Latency is zero;
- Bandwidth is infinite;
- The network is secure;
- Topology doesn't change;
- There is one administrator;
- Transport cost is zero;
- The network is homogeneous.
Types of links on Distributed Systems
- Fair loss: sender has no way to check delivery of message. Message is repeateadly send and will eventually be delivered
- Finte duplication: Send messages won't be delivered infinitely many times
- No creation: A link won't send messages
- Perfect link: checks message sequence number has already been processed and discars if so. Provides the following guarantees:
- Realible delivery: every message sent once will eventually be delivered
- No duplication
- No creation: only delivers actually sent messages
Types of delivery
- Exactly-once
- At-most-once: doesn't expect delivery confirmation
Broadcast
It's a algorithm used to disseminate information among a set of processes
- Realiable broadcast
- Atomic broadcast
- Zookeeper Atomic Broadcast (ZAB) is an implementation of the above
Consensus
To reach consensus we need the following:
- Agreement: decision must be unanimous
- Validity: agreed value must be proposed by one of the participants
- Termination: agreement is final when all reach decision state
In the paper FLP Impossibility Problem it's stated that it's impossible to reach consensus and handle possible node failures without setting some upbound time to reach it. This means that distributed systems must have a notion of timing and in that way be synchronous
Some algorithms are:
- Paxos
- Multi-paxos
- Fast paxos
- Egalitarian paxos
- Flexible paxos
- Raft
Paxos
A participant in Paxos can take one of three roles: proposer, acceptor, or learner
Raft
Simpler than Paxos. Can take 3 roles: Candidate, Leader or Follower.
Failure Algorithms
Many algorithms rely in heartbeats (i.e Akka). However this approach has the downside of relying on ping freqeuncy and timeouts instead actually checking the process itself
Timeout-free failure detector avoids these timeouts and operates umder asynchronous system assumptions.
Another approach is using outsourced hearbeats. In case of a failure alive response of a process. The main process requests other processes to check if the possibly failing one responds to them. If the answer is afirmative, the initial process considers it alive.
Phi-Accrual Failure detector uses mulitple factors to decide how alive the node is instead of considering this a binary decision
Gossip and Failure detection defines a list of other members and sets a counter for each one. Everytime the member responds, the counter increases. The list is shared between nodes which allows a node to keep working even if it's failing to one of the members
Failure notification service (FUSE) divides the nodes into groups. If one of the nodes fails, the whole group will fail as by lacking a response from one of the nodes in the groups it automatically shuts downs
Leader election
Split-brain occurs when two leaders serving the same purpose are elected but unaware of each other.
Some algorithms for leader election:
- Bully: each process is assigned a rank. On election the one with highest value is the leader
- Violates safety guarantee as in the presence of network partitions a split brain occurs
- Next-in-line failover
- Candidate/ordinary optimization
- Invitation
- Ring
Consistency models
- Strict: theoretical only. After write X everything reads the new version
- Linearizability: at some point in time the change must appear instant (linearization point)
- Sequential consistency: linearizability is only required for operations from the same node processs. Between processes the order can be anything
- Required casuality between sequential writes
- Databases like dynamo use vector clocks to establish this casuality
- Eventual Consistency: doesn't define a hard time bound for the latest write value to be read by the client. In practice the update is quite fast but the client doesn't have any guarantees of having the latest data
- Tunable consistency
- Consistency levels that consist of a majority of the nodes to decide on a value is called a quorum
Session models
Session models allow to reason about the state of a distributed syste from the perspective of a single client interacting with the system
- Read-own-writes: read operations reflect the previous writes
- Monotonic reads: any read that has observed a value cannot see a older one later on
- Monotonic writes: writes propagate to others in the same order as the writer
- Writes-follow-reads: write operations are ordered after the writes whose effects were observed by the precious reads executed by the same client
Strong eventual consistency abd CRDT's
A middle ground where we allow the nodes to reconcile and merge the different states. One of most proeminent algorithms is Conflict-Free Replicated Data Types (CRDT)
Distributed transaction
Needed to make sure the transaction is atomic. Some algorithms used are:
- Two-phase commit: coordinator proposes commit (prepare message). The nodes vote and, only if unanimous, coordinator sends commit message. Otherwise it's aborted
- As a single node failure can lead to aborts, spanner uses 2PC over paxos groups which improves availability
- Threee-phase commit
- Calvin
Links
https://www.alexdebrie.com/posts/dynamodb-eventual-consistency/ Database internals from Alex Petrov